一. 初识 HACMP 心跳
HACMP 软件主要监控 4 种故障:节点,网卡,网络,应用。其中前三种都是通过心跳来监控并产生事件响应的,我们可以看出使用 HACMP 集群,可谓玩的就是心跳。如果不了解心跳的过程和基本原理,使用 HACMP 搭建起来的高可用的平台就可能是高不可用。
其实 HACMP 的心跳并不复杂高深,像所有的 HA 软件一样,心跳包是用来传递节点的状态信息,HACMP 的心跳包从最高的 IP 地址依次单向流动到最低 IP 地址,然后再返回到 IP 地址最高的节点形成一个单向循环的环路。每一个物理子网都会有一个心跳环路,包括串口心跳和磁盘心跳这些点对点的心跳,在广义上也是各自独立的心跳环路。每个环路我们称之为一个心跳网络。其心跳过程我们可以参看下图,Node3 有最高的 IP 地址 192.168.1.3,它是该心跳环路的 Group Leader。 Node3 产生的心跳包发送给 Node2,Node2 产生的心跳包发送给 Node1,Node1 则发送给 Node3 形成一个环路。
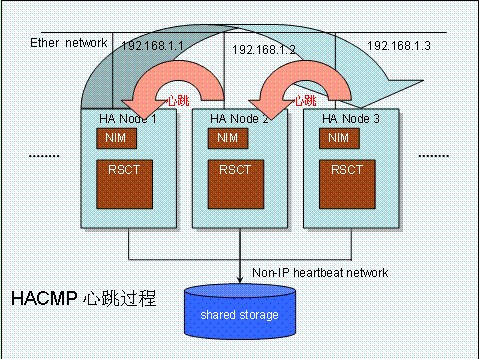
对于 HACMP 集群来说,至少需要 2 个心跳网络来保证心跳网络的冗余,而且更进一步,至少需要 2 种不同类型的心跳网络保证更高的可靠性,比如,一个 IP 网络心跳,一个磁盘心跳。之所以对心跳网络可靠性有如此高的要求,除了我们之前描述的心跳网络的重要作用以外,还有更重要的原因:如果 2 个节点间心跳通信完全中断后,他们都会认为对方已经宕机,然后都在本地启动应用,并同时去争抢磁盘资源,有可能导致数据出现风险,即所谓的 split-brain 事件。所以 HACMP 包括其他的 HA 的集群应用都有一个很重要的前提,就是要求在任何时刻至少存在一个可用的心跳网络在节点间传递信息。
二. 再看 HACMP 心跳
从 HACMP5.1 版本以后,HACMP 的心跳已经交由 RSCT(Reliable Scalable Cluster Technology)这一套中间层软件来实现。RSCT 相当于是一个集群应用与集群管理的中间通讯平台,它提供了丰富的集群功能简化了集群应用开发的复杂性。在其他的一些软件,比如 IBM CSM 集群管理软件和 HMC 上的部分管理功能都是通过 RSCT 的组件来实现的。
再细分来看,负责心跳的是 RSCT 中的 Topology Services 模块。我们下面先了解一下 Topology Services 的初始化过程。Topology Services 的核心进程是 /usr/sbin/rsct/bin/hatsd 。hatsd 启动后就开始广播本节点信息同时侦听其他节点的信息,经过自举、推举、还有一段时间等待(其过程有点类似于以太网交换机通过 spanning-tree 协议选举 root 节点),最后在该子网中找出所有节点里一个 IP 地址最高的,将它定义为 group leader。 Group leader 作为一个权威节点负责该子网中节点状态信息的收集,管理,更新和发布。至此,心跳网络就完成了其初始化过程开始正常心跳。另外,为防止 Group Leader 宕机,还定义了 IP 地址第二高的节点作为 Group Leader 的监控节点称之为 Group Leader Successor,它负责监控 Group Leader 状态,在必要时可以弹劾并成为 Group Leader。
在心跳网络建立以后,网络状态的监控被分为两部分,一是网卡物理状态的监控;一是逻辑上的网络链路状态监控。网卡物理状态的监控是通过为每一块网块创建一个监控进程(NIM)来实现的,当网卡状态改变会立刻通知 RSCT,比如网卡 Link down 的信息就会被 NIM 立刻发现并产生 Network adaptor failure 的事件。
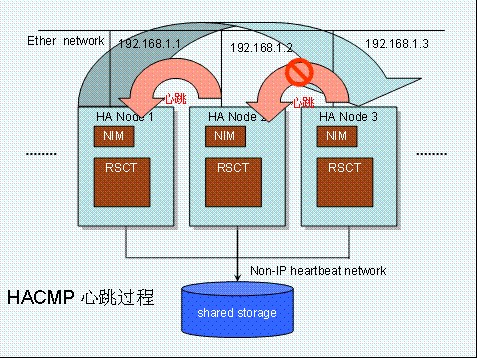
另一方面,hacmp 心跳故障判断还能从逻辑上分析判断网络状态。我们以下图为例。假设在运行过程中,Node3 到 Node2 之间的网络发生意外中断,但是 Node3 网卡的链路状态仍然为 UP,此时物理的网卡监控不会做出反应。然而心跳包会开始丢包,Node2 会发现无法收到 Node3 的心跳包,但此时并不能确定到底是 Node2 还是 Node3 网络出现故障。为了进一步确定故障,Node3 会通过 RSCT 走别的心跳网络发命令给第三个节点(node1),让第三个节点(Node1)分别去 ping Node2 和 Node3。如果故障点在 Node3 上面,那么显然 ping Node3 会失败,于是确定故障位置在 Node3 上面,最后产生一个的 Network adaptor failure 的事件通知给 HACMP。
三. 2 个节点的 HACMP 集群
我们从上文可以发现,准确判断网络故障点的位置需要“第三个节点”做仲裁。只有 2 个节点的 HA 集群如何实现正确判断?从一般的逻辑判断上来说,2 个节点之间出问题一定是公说公有理,婆说婆有理,必须要有第三方来做仲裁。
在只有 2 个节点的 HA 集群中,为了解决这个问题,HACMP 需要配置一个文件来设置一些第三方的一个仲裁 IP 地址。当心跳故障发生时,2 个节点都会去试图从本机去 ping 这些仲裁 IP 地址。能正确的 ping 通则表明本节点的网络正常,从而判断出故障点需要注意的是,仅仅是在网络心跳发生问题时,RSCT 才会调用网络诊断的进程去使用这些仲裁 IP,在正常状态下,这些仲裁 IP 不会参与到心跳过程。
这些仲裁 IP 的选择可以是子网的网关,也可以是子网中其他的某一节点 IP 地址。如果有多个子网,需要为每个子网挑选一个仲裁 IP 地址,把他们写成一个 list 保存到一个配置文件(netmon.cf)中。该配置文件的存放位置在 /usr/es/sbin/cluster/netmon.cf。在两个节点的 HA 群里同步配置的过程中,如果没有配置 netmon.cf 可能会弹出一个 warning 的信息提示该文件需要配置。
在配置 netmon.cf 后,RSCT 的进程启动后,会逐条把其中的 IP 读取进来,作为仲裁 IP 使用。我们可以在 nmDiag.nim.topsvcs.xxx 这个日志文件中看到这样的信息。
06/18 19:01:55.387: read_ping_configuration:Entered for adapter en0
06/18 19:01:55.387: read_ping_configuration:File /usr/es/sbin/cluster/netmon.cf opened
06/18 19:01:55.387: read_ping_configuration:Read [192.168.21.130 ] from file.
06/18 19:01:55.387: read_ping_configuration:gethostbyname (192.168.21.130) was successful.
06/18 19:01:55.387: read_ping_configuration:Read [172.32.16.3] from file.
06/18 19:01:55.387: read_ping_configuration:gethostbyname (172.32.16.3) was successful.
06/18 19:01:55.387: read_ping_configuration:Read 2 ping addresses.
四. 其他一些细节
4.1 RSCT/HACMP 日志文件
关于 HACMP 心跳的日志存放在 /var/ha/log 目录下。其主要可供分析的有:
(1)nim.topsvcs.enX (enX 为网络端口名 ) 该文件对应的记录了网卡 enX 的网络监控进程的启动,心跳和退出的详细日志。
(2)nmDiag.nim.topsvcs.enX 该文件记录了在心跳出现丢失后,RSCT 对网络拓扑的逻辑分析判断的过程。
(3)Topsvcs.<pid 进程号 >.<cluster name> 该文件是 topsvcs 的主进程日志文件,记录 topsvcs 进程的启动过程,以及心跳网络拓扑改变等重要的事件信息。
4.2 心跳网络状态查询命令
我们一般都知道 hacmp 的状态可以通过 /usr/sbin/cluster/clstat 来查看,还有一个命令可以更详细的查看当前集群心跳状态。 lssrc –ls topsvcs 如下图:
# lssrc -ls topsvcs | more
Subsystem Group PID Status
topsvcs topsvcs 315610 active
Network Name Indx Defd Mbrs St Adapter ID Group ID
net_ether_01_0 [ 0] 2 1 S 192.168.21.150 192.168.21.150
net_ether_01_0 [ 0] en0 0x808820f2 0x808820fc
HB Interval = 1.000 secs. Sensitivity = 10 missed beats
Missed HBs: Total: 0 Current group: 0
Packets sent : 1078 ICMP 0 Errors: 0 No mbuf: 0
Packets received: 866 ICMP 0 Dropped: 0
NIM's PID: 307250
net_ether_01_1 [ 1] 2 1 S 172.16.21.1 172.16.21.1
net_ether_01_1 [ 1] en1 0x808820f3 0x808820fc
HB Interval = 1.000 secs. Sensitivity = 10 missed beats
Missed HBs: Total: 0 Current group: 0
Packets sent : 1078 ICMP 0 Errors: 0 No mbuf: 0
Packets received: 434 ICMP 0 Dropped: 0
通过分析心跳包的丢包数量和频率可以判断网络的可靠性和负载情况,一方面可以用来分析和解释异常的 HA 备机切换动作,另一方面可以用来分析系统问题并通过调整系统参数来均衡负载。建议在设计 HA 集群的时候不要使用负载过大的 TCP/IP 网络或者 IO 负载很大的磁盘来做心跳。
小结
HACMP 集群的各种网络故障的分析和判断都是由 RSCT 心跳来实现的,网络故障的判断正确与否也直接影响了 HACMP 对应用的切换和还原,所以了解心跳的过程与原理对于设计与配置 HACMP 高可用集群具有重要的意义。
From:
http://www.ibm.com/developerworks/cn/aix/library/0811_wangrong_hacmp/index.html
------------------------------------------------------------------------------
Blog: http://blog.csdn.net/tianlesoftware
网上资源: http://tianlesoftware.download.csdn.net
相关视频:http://blog.csdn.net/tianlesoftware/archive/2009/11/27/4886500.aspx
DBA1 群:62697716(满); DBA2 群:62697977(满)
DBA3 群:62697850 DBA 超级群:63306533;
聊天 群:40132017
--加群需要在备注说明Oracle表空间和数据文件的关系,否则拒绝申请
分享到:




相关推荐
hacmp 真机现场实测 心跳线配置和切换视频
HACMP相关的知识,详细介绍了心跳方面的内容,比较实用,值得一看。
配置hacmp磁盘心跳和永久IP地址配置hacmp磁盘心跳和永久IP地址
HACMP 的心跳简介.doc HACMP 的心跳简介.doc
AIX5.3_HACMP+oracle双机安装配置(IP心跳)
HACMP状态查看,这个是在与IBM工程师沟通过N次,参考了好几个文档后写的.
HACMP_source,v,HACMP_source,HACMP_source
hacmp检查方法 文件版本 2 目录 3 1)HACMP 检查原理和要点: 5 2)HACMP检查简表 5 3)HACMP检查内容: 7 a)检查HACMP patch版本: 7 b)对HACMP现有配置作verify 8 c)检查共享文件系统和逻辑卷是否同步: 10 d)...
HACMP日常维护操作
HACMP 串口心跳设置.txt HACMP 主要进程.pdf HACMP 概念.pdf HACMP 集群规划.pdf HACMP.pdf HACMP.txt HACMP故障.txt HACMP进程.txt IBM HACMP集群配置.pdf Service ip 2种工作方式.txt 服务 IP 地址....
IBM HACMP配置例子,便于配置HACMP
HACMP 5.3在AIX 5.3上的安装
HACMP配置文档(AIX HACMP 完整安装配置过程)
IBM 集群软件HACMP 安装和配置的详细步骤
IBM au54 HACMP HACMP System Administration I
配置HACMP全过程 学习HACMP的一第一步 内容详细的介绍了原理和步骤
IBM AIX HACMP培训教程
AIX HACMP很值得推荐一看的HACMP配置
我的AIX HACMP学习笔记